
DeepSeek AI. WTF is going on?
Why it's a big deal beyond the daily "LinkedIn hype".

In early 2023, I sat at our Jua.AI (AI for weather-dependent energy trading) company offsite when Marvin, our Co-Founder, walked us nontechnical peasants how AI actually works.
From “Here’s why this is a technological leap” to “the ‘transformer models’ may seem like magic, but here’s how they work’ to ‘who are the big players in the space,’ Marvin walked us through it all.
I (Head of Product at the time) distinctly remember, halfway through that presentation, locking eyes with Andreas (Co-Founder & CEO) and thinking, “We cannot defend a business solely with around a model technology forever.”
We were ahead in AI, which was a huge advantage, but we were terrified that companies like Microsoft or Google could just dunk on us by throwing more money at the problem.
It was a stark reminder: we are building a company for markets in the future, not just for today. Even if we have an advantage today, there’s a good chance we won’t tomorrow, and we need to be prepared for that.
So we decided to make big changes in Jua’s overall direction to establish other defendable moats (things that are hard/impossible to copy) to build a business around.
All the hoopla around DeepSeek is a strong indication that our bet was right on the money, which has far- reaching implications for the AI and tech industries more broadly.
This isn’t about DeepSeek, exactly, nor is it that DeepSeek is from China, per se.
It’s about something it’s proving.
Let’s dig into it with a business eye:
What is DeepSeek?
What’s the big deal about it?
Why OpenAI and Co. are sweating
Why NVIDIA is nervous (also sweating)
Leah’s hyperbolic take?
Further Sources
I’m running the 31st of January a free Webinar with Kieran Flanagan, (SVP Marketing Hubspot), where we do a practical demonstration on “How to Identify Growth Opportunities with AI” incl. time for a Q&A.

1. What is DeepSeek?
I’m going to simplify this as much as possible, as there are better in-depth explanations out there on what DeepSeek is from people who write about AI daily
(I link some highly recommended public sources at the end of this article. Especially ComputerPhile’s Video.)
TL;DR - It’s a new, cheap, small, open-source Model
DeepSeek is a company out of China offering access to a model which it claims to be:
Performing at the levels of ChatGPT, Claude, etc.
Costing a fraction to use, train and run.
Public about how it exactly works.
DeepSeek is really two things - V3 and R1. Let’s go over each.
Deepseek V3
Their V3 model is the closest you have to what you probably already know; it’s a large (671B parameters) language model that serves as a foundation, and it has a couple of things going on - it’s cheap and it’s small.
Cheap
When we use an all-purpose model that can answer all sorts of questions without any qualification, then we have to use the entire “brain” or parameters of a model every time we want an answer.
A newer, much cheaper approach to this is called a Mixture of Experts, which is what DeepSeek (and probably also the other ones if they arent yet) is leveraging:
A Mixture of Experts (MoE) is a way to make AI models smarter and more efficient by dividing tasks among multiple specialized "experts." Instead of using one big model to handle everything, MoE trains several smaller models (the experts), each focusing on specific types of data or tasks. When a new input comes in, a "gate" decides which experts should work on it, activating only the most relevant ones. This makes the model faster and more scalable because it doesn't have to use all its resources all the time—just the right experts for the job. It's like a team of specialists instead of a single generalist, leading to more precise and efficient decision-making.
Small
A thing that makes the model come down in “size” is called Distillation, which allows it to be run on much smaller machines (like your graphics card instead of a cluster of supercomputers):
Distillation in AI is like compressing knowledge from a big, complex model into a smaller, faster one without losing too much accuracy. A large model (the “teacher”) generates predictions, and a smaller model (the “student”) learns to mimic those outputs. This makes AI systems more efficient, reducing cost and speed while keeping performance strong. It’s like having an expert explain something in a way that a beginner can still understand and use effectively. It’s probably not good enough in the craziest edge cases, but it can handle simple requests just as well.
Both OpenAI and Anthropic already use this technique as well to create smaller models out of their larger models.
DeepSeek R1
DeepSeek’s R1 model builds on the on this foundation of the V3 model to incorporate advanced reasoning capabilities, making it effective at complex tasks such as mathematics, coding, and logical problem-solving. In essence, R1 enhances the capabilities of V3 by adding specialized reasoning functions.
It can solve complex problems that require multiple steps much better than V3 (and some other available models). This means it excels in quality
Quality
A big deal about their R1 model is how it tries to solve complex problems through something called “Chain of Thought”
Chain of Thought (CoT) in AI improves reasoning by making the model think step by step, like how humans break down complex problems. Instead of jumping straight to an answer, the AI explains its thought process along the way. This helps it handle tasks like math, logic, and coding more accurately. Think of it as showing its "work" rather than just giving the final answer—kind of like how you’d solve a math problem by writing out each step.
The other bigger players are also doing this, with OpenAI having pioneered this approach, but they don’t tell you, as part of their business model, how they are doing it exactly.
Let’s look at a funny example of Chain of Thought:
“I broke DeepSeek AI 😂”
A Reddit user wrote a post yesterday titled “I broke DeepSeek AI 😂” in which he confused the model and made it reason forever.
While it’s funny, it shows exactly (and transparently!) how the model is trying to solve the complex question in various different broken down steps before it stops completely.
Video source: /u/SnarkyStrategist
(Another great example is in this video by Computerphile about stacking different boxes.)
To train their model to improve at chain of thought reasoning, DeepSeek used a reinforcement learning process (think of it like training a dog - good behavior gets treats, bad behavior gets ignored or corrected, and eventually, the dog learns what works best). My bet is that this was “helped” (cough cough) by other publicly available models.
This leads to another funny situation, which is now OpenAI saying that DeepSeek was “using our output to train their model”. So kind of “stealing” OpenAI’s training data that OpernAI kinda stole from everyone else.
A comment I saw on LinkedIn (which I can’t find anymore, someone found it!) summarized it like this, and I hate to make it pretty:

2. What’s the big deal?

As I said in the introduction, this is not about DeepSeek per se. It is also not about the fact that this model is from China, what it can potentially do with your data, or that it has built-in censorship.
It’s that it is cheap, good (enough), small and public at the same time while laying completely open factors about a model that were considered business moats and hidden.
Having an all-purpose LLM as a business model (OpenAI, Claude, etc.) might have just evaporated at that scale. And that’s why OpenAI & Co and NVIDIA are sweating.
Why OpenAI and Co. are sweating
Building “a” model is not hard. However, building an all-purpose great language model is very hard and mostly expensive. At least, that has been the current reality, making the industry squarely in the firm hands of big players like OpenAI, Google, Microsoft.
We had various jumps in training efficiency and other optimizations, but the leap from “prohibitively expensive to even attempt” to “you can probably run this on your graphics card to deal with most of your problems” is massive. And before DeepSeek, seemed impossible.
We can apply some standard Market Theory to this. The money in markets is usually segmented into different parts. Enterprise, midmarket, and consumer problems:
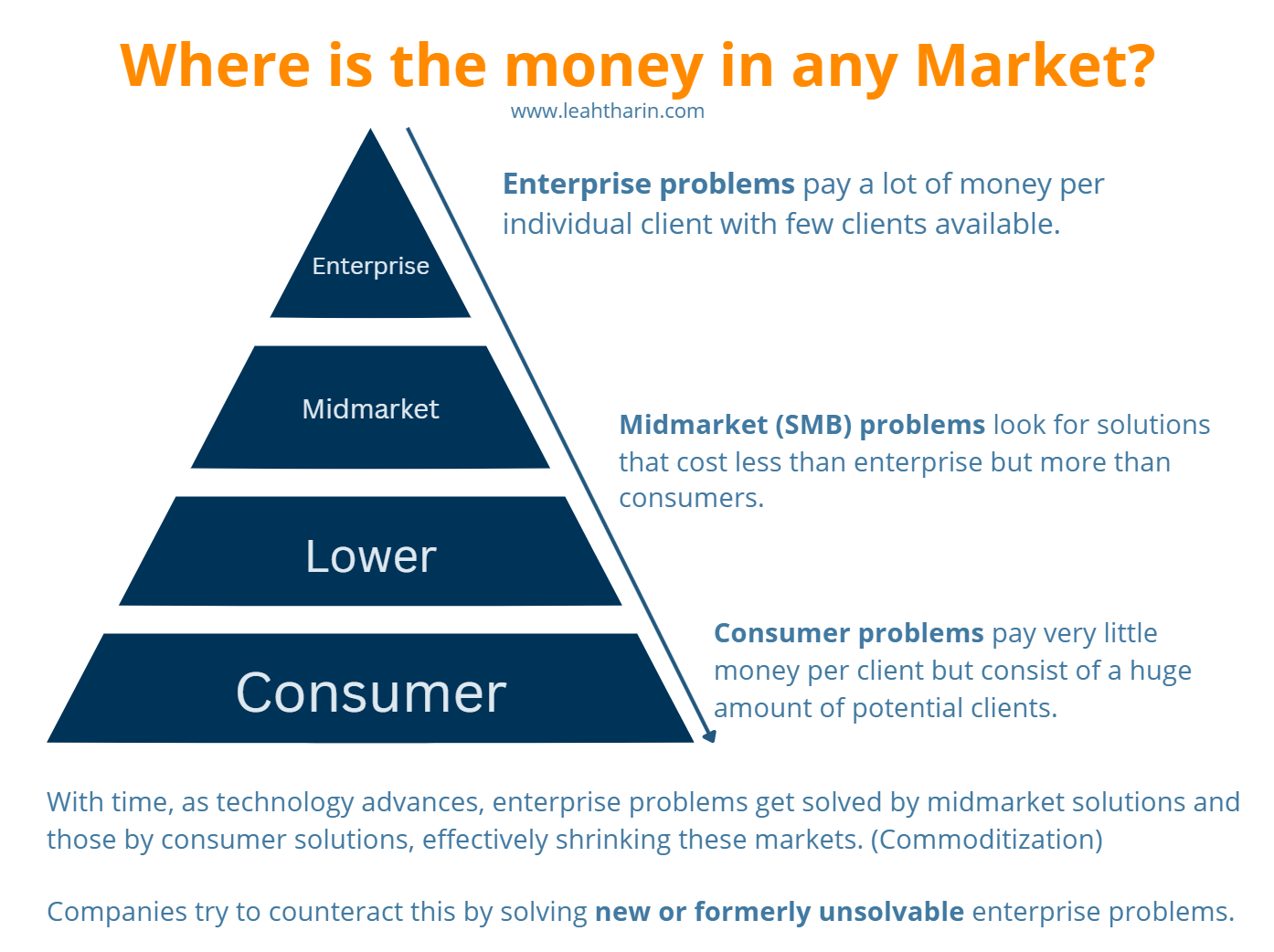
Therefore, the “type” (whether it’s midmarket, consumer, or enterprise) of your problem dictates how much the market is willing to pay for it.
